La informática ha estado evolucionando cogiendo conceptos de otras áreas y adaptando esos conceptos. Las redes neuronales, por ejemplo, proceden de observar el cerebro humano; la aplicación de patrones de diseño y de soluciones conocidas es común en arquitectura; ¿alguna vez te has sentido como un doctor preguntando al paciente qué le pasa mientras debugueabas?. Un algoritmo genético proviene del campo de la genética, y muchos términos se comparten entre sí.
Un poco sobre genética
Empecemos echando un ojo a la biología. Una visión extremadamente simplista de la selección natural y la evolución implica a multiples individuos, cada uno con diferentes características, escogiendo a quien es el más apto durante varias generaciones.
Vamos a usar algunos de estos conceptos del campo de la genética y aplicarlos a la informática:
- Gen: la información mínima con la que vamos a trabajar.
- Cromosoma / genotipo: la lista de genes que conforman un individuo.
- Población / fenotipo: una lista de cromosomas.
También vamos a definir algunos operadores:
- Mutación: el cambio del estado en uno o más genes dentro de un cromosoma.
- Recombinación: combinar 2 cromosomas para generar uno nuevo.
- Selección: escoger el cromosoma más apto.
Mezclando la genética con la informática
Mutaciones
La mutación de un gen sucede de acuerdo a una determinada probabilidad, normalmente definida por el usuario, pero podría ser parte de la definición del problema: quizás queremos tener hasta 5 mutaciones en un cromosoma, quizás 10, o tal vez 1. Nótese que el gen donde sucede la mutación debería ser completamente aleatorio.
La mutación cambiará el valor que contiene el gen. Este cambio puede escribir un valor aleatorio entre límites, con una distribución uniforme o gaussiana dependiendo de la definición del problema. También puede intercambiar valores con otro gen del mismo cromosoma escogido de forma aleatoria.
Establecer estas mutaciones es parte de la definición del problema: qué mutaciones pueden suceder y con qué probabilidad.
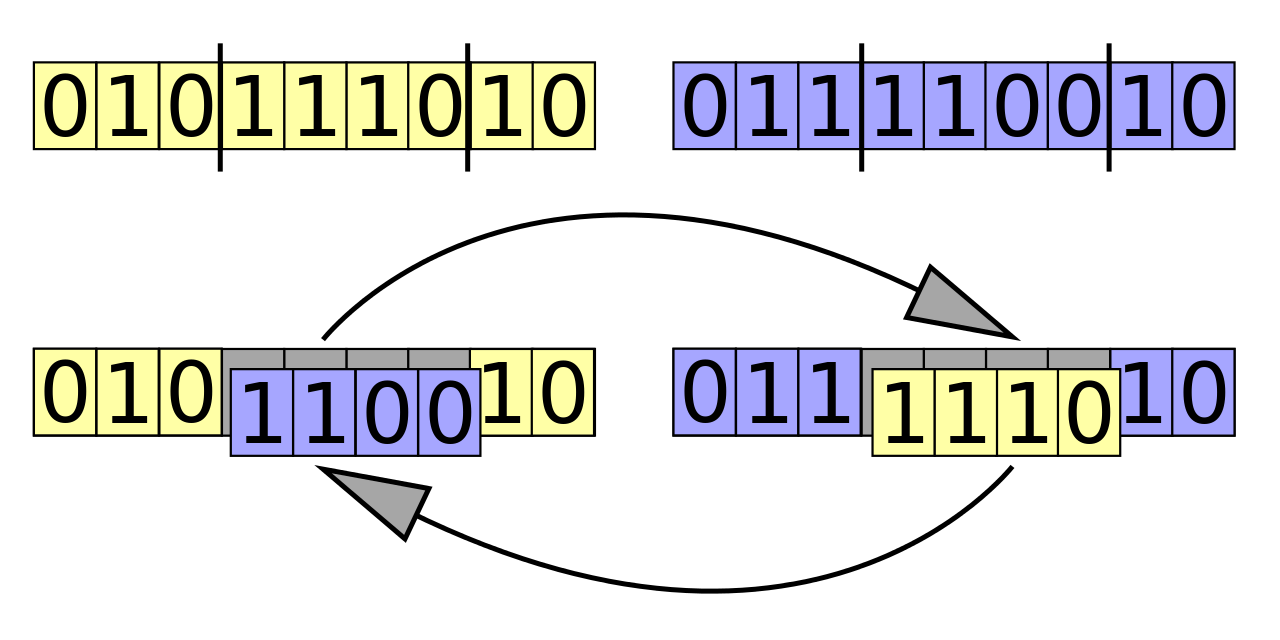
Recombinaciones
De forma similar a lo que pasa con la mutación, la recombinación tiene sus propias operaciones que pueden establecerse o no dependiendo del problema. La operación más común consiste en escoger un «punto de recombinación» (o multiples puntos) e intercambiar las partes de los cromosomas para generar uno nuevo.
Por ejemplo, si tenemos los cromosomas A y B, podemos dividirlos en A1,A2,A3 y B1,B2,B3, y luego generar A1,B2,A3 y B1,A2,B3. El punto de recombinación debe cortar el par de cromosomas en el mismo punto.
Nótese que este método puede no ser aplicable a todos los problemas porque puede generar soluciones inválidas al problema que queremos resolver.
Selecciones
Finalmente, el proceso de selección escoge (normalmente) al mejor grupo de cromosomas. Para ello, el usuario necesita definir una función de aptitud, que depende del problema en particular, para evaluar cuán apto es el cromosoma. Un cromosoma más apto tendrá un valor mayor que otro.
Una vez que todos los cromosomas tenga su aptitud evaluada, tendremos que escoger a los mejores. De nuevo, hay varios métodos para hacer esto. El método más sencillo, es escoger los cromosomas con mayor valor de aptitud, que son los que esperamos que más se acerquen a la solución de nuestro problema.
Cómo funciona un algoritmo genético
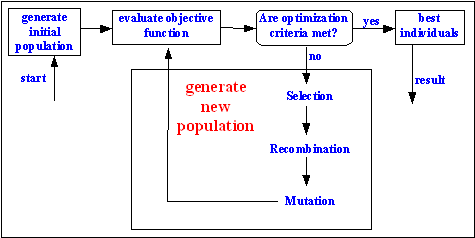
En general, el proceso es:
- Aplicar las mutaciones a todos los cromosomas. Como se ha dicho, algunos cromosomas podrían no mutar mientras que otros podrían tener múltiples mutaciones.
- Generar nuevo cromosomas mediante recombinación. Este paso podría saltarse si no tiene sentido para nuestro problema.
- Aplicar la función de aptitud y seleccionar a los mejores cromosomas. Los cromosomas no seleccionados serán descartados.
- Volver al paso 1.
Este es un proceso iterativo y continuará hasta que algunas condiciones se cumplan. Normalmente, se requiere una mezcla de las siguientes condiciones para finalizar este proceso iterativo. Las condiciones también son parte de la definición del problema.
- El valor de aptitud más alto no ha cambiado en las últimas X iteraciones. Esto implica, muy probablemente, que has encontrado la mejor solución.
- El valor de aptitud más alto está dentro de un umbral de aceptabilidad. La solución que se ha encontrado puede no ser la mejor, pero es suficientemente buena.
- Finalizar después de X iteraciones. Esto se suele poner como garantía para evitar un posible bucle infinito.
Modelando un problema para un algoritmo genético
Queremos enviar una lista de 1000 ficheros cuyo tamaño varía desde los 0.5MB a los 10MB. Estas son las restricciones:
- El tamaño de los paquetes debe ser menor de 30MB (asumamos que no puedes subir archivos más grandes de ese tamaño).
- Queremos minimizar el número de paquetes que queremos subir, así que el tamaño del paquete debe acercarse lo más posible a los 30MB pro no puede ser mayor.
- Podemos aceptar un umbral de 500KB, así que si encontramos una lista de ficheros de 29.5MB aceptaremos ese paquete y no buscaremos uno mejor.
- Para simplificar el problema, aceptaremos un paquete de fichero de hasta 30MB, borraremos esos ficheros de la lista y repetiremos el proceso. Tan solo necesitamos encontrar el primer paquete de ficheros.
Para modelar el problema, cada fichero será un gen, la lista entera de ficheros será un cromosoma, y la población será las posibles variaciones de la lista de ficheros. Podemos empezar con un tamaño de población de 40 posibles soluciones generadas de forma aleatoria.
Necesitamos definir qué operadores vamos a usar.
- Mutaciones: nos centraremos en intercambiar genes, así que cualquier operador que haga este intercambio es suficiente.
- Recombinaciones: podemos aplicar un «greedy crossover», que parece aplicable para nuestro caso, o quizás no hacer nada.
- Función de aptitud: comprobaremos los primeros archivos de la lista sumando sus tamaños hasta que estemos lo más cerca de los 30MB sin sobrepasarlos; cuanto más cerca mejor.
Después de modelar el problema, podemos configurar una librería de algoritmos genéticos con esta información. La mayoría de las librerías deberían tener suficientes operadores por defecto, así que como se ha dicho, tan solo debería ser configurar la librería correctamente y ejecutarla; normalmente no deberías necesitar implementar operadores propios.
Últimas palabras

Como has visto, el proceso global de un algoritmo genético es bastante simple y fácil de entender, pero no hemos mirado al abismo, ni siquiera a la superficie.
Los operadores usados por el algoritmo normalmente determinan el rendimiento. Usar un operator erróneo podría reducir el rendimiento o incluso hacer que el algoritmo falle. Podría degenerar a una búsqueda completamente aleatoria en vez de ir mejorando con el tiempo.
Deberías usar una librería porque oculta toda la complejidad que los operadores pueden tener. Hemos mencionado brevemente el «greedy crossover», que es el usado para resolver «el problema del viajante». Hay estudios intentando mejorar el rendimiento, y el tema es bastante complejo de seguir.
¿Alguna vez has pensado en usar un algoritmo genético para resolver un problema?



